ChatGPT request assembly architecture
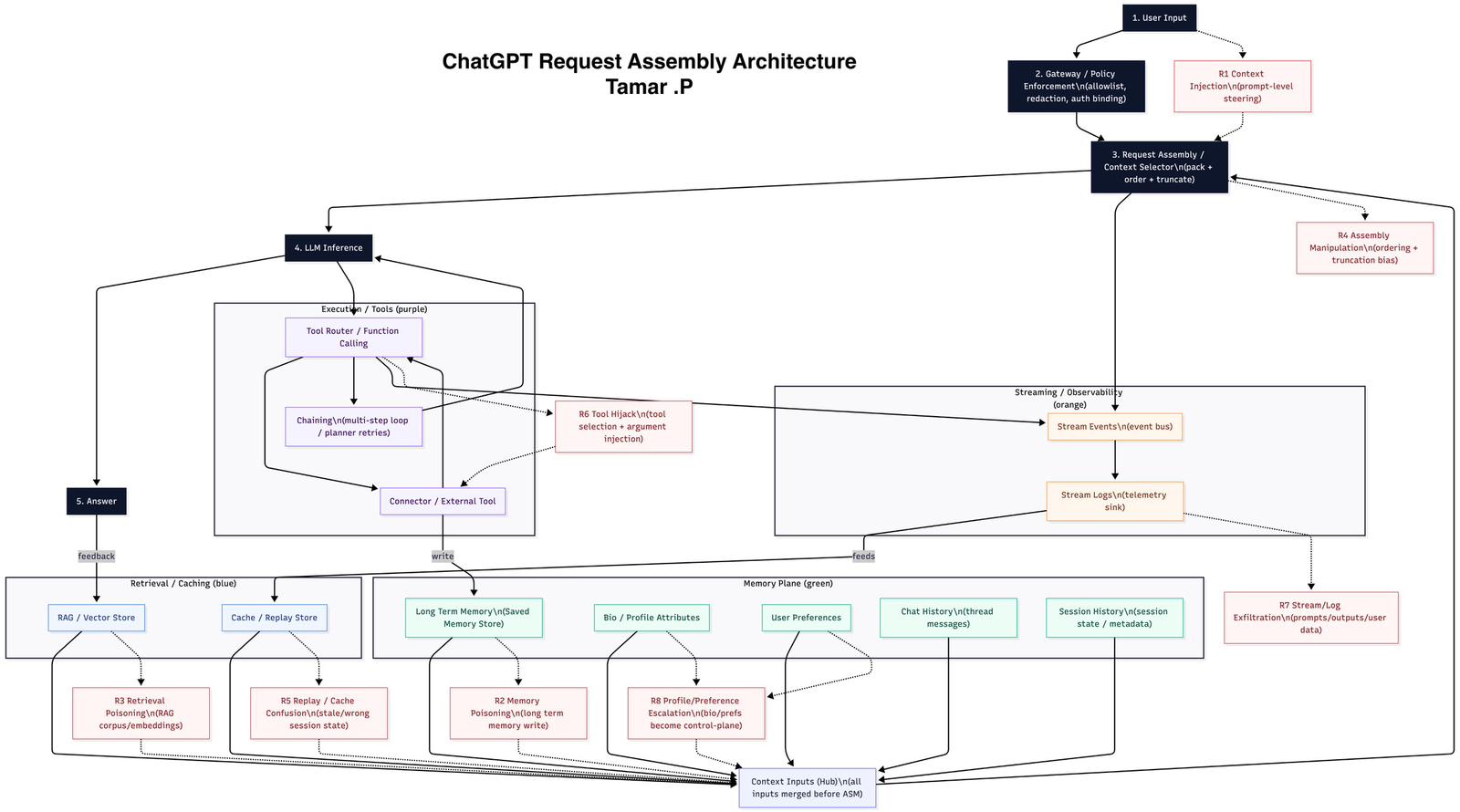
What this diagram is
This is an author-mapped reference diagram that models how a chat request can be assembled and executed across:
- Policy/Gateway enforcement
- Request assembly / context selection
- LLM inference + tool execution
- Retrieval/caching inputs
- Memory inputs
- Streaming/observability outputs
Provenance note: This is not a vendor-published internal architecture diagram.
According to the author, the mapping was derived from external observation (including network-level signals and repeatable behavior). This page intentionally does not include a step-by-step methodology; treat the diagram as a reference model for analysis and review.
How to read it
1) The primary request path (numbered boxes)
- User Input
- Gateway / Policy — enforcement (allowlist), redaction, auth binding
- Request Assembly / Context Selector — pack + order + truncate
- LLM Inference
- Answer (with a feedback signal)
2) Planes (color legend)
- Execution / Tools (purple): tool routing, multi-step chaining, connectors/external tools
- Retrieval / Caching (blue): RAG/vector-store retrieval and cache/replay concepts
- Memory plane (green): long-term memory, profile/bio attributes, preferences, chat history, session history
- Streaming / Observability (orange): event stream + telemetry/log sink
3) Context Inputs Hub
The Context Inputs (Hub) is the conceptual merge point shown at the bottom: it represents that multiple inputs can be merged before request assembly.
Components (as labeled in the diagram)
Gateway / Policy
A control point for:
- allowlisting / policy enforcement
- redaction
- binding authorization to the request
Request Assembly / Context Selector
A packaging step that:
- selects eligible inputs,
- orders them,
- truncates to constraints, and produces the final model request payload.
Execution / Tools (purple)
- Tool Router / Function Calling
- Chaining (multi-step loop / planner retries)
- Connector / External Tool
Retrieval / Caching (blue)
- RAG / Vector Store
- Cache / Replay Store
Memory plane (green)
- Long Term Memory (saved memory store)
- Bio / Profile Attributes
- User Preferences
- Chat History (thread messages)
- Session History (session state / metadata)
Streaming / Observability (orange)
- Stream Events (event bus)
- Stream Logs (telemetry sink)
Risk checkpoints (R1–R8)
The red boxes mark risk checkpoints used for review. They are intended as analysis anchors (threat-model checkpoints), not as claims about any specific vendor implementation details.
- R1 Context Injection (prompt-level steering)
- R2 Memory Poisoning (long-term memory write)
- R3 Retrieval Poisoning (RAG corpus/embeddings)
- R4 Assembly Manipulation (ordering + truncation bias)
- R5 Replay / Cache Confusion (stale/wrong session state)
- R6 Tool Hijack (tool selection + argument injection)
- R7 Stream/Log Exfiltration (prompts/outputs/user data)
- R8 Profile/Preference Escalation (bio/prefs become control-plane)
Intended use
Use this page as a reference map for:
- analyzing why answers change (context selection, memory inputs, retrieval inputs, tool execution),
- structuring security review around the R1–R8 checkpoints,
- communicating system boundaries and review scope to practitioners.
References (feature-level; not internal placement)
- Memory (saved memories / chat history): https://help.openai.com/en/articles/8983136-what-is-memory
- Memory FAQ: https://help.openai.com/en/articles/8590148-memory-faq
- Function / tool calling: https://developers.openai.com/api/docs/guides/function-calling/
- Tools overview: https://developers.openai.com/api/docs/guides/tools/
- Connectors / apps in ChatGPT: https://help.openai.com/en/articles/11487775-connectors-in-chatgpt
- OWASP Top 10 for LLM Applications: https://owasp.org/www-project-top-10-for-large-language-model-applications/