LLM-Led vs Orchestrator-Led Tool Execution Control-Plane Placement Tradeoffs
Abstract
When an LLM can call tools, the core architecture decision is where execution authority lives: inside the model loop, or outside it in an orchestrator/control plane.
This article compares two patterns:
- LLM-led execution: the model selects tools and produces tool-call arguments; the application executes those calls with limited external governance.
- Orchestrator-led execution: the model proposes intents/steps; an external orchestrator validates, authorizes, budgets, and executes.
Security and policy enforcement are one dimension of the broader tradeoff set (reliability, debugging, observability/auditability, latency, and cost governance).
Definitions (used in this article)
- Execution authority: the component that can cause external side effects (writes, deletes, payments, privileged actions).
- Control plane: decision logic for routing, validation, authorization, budgets, approvals, retries, and stop conditions.
- Data plane: the code path that performs tool calls and causes side effects (actual external calls and state changes).
- Policy enforcement placement: where allow/deny is enforced before side effects.
If you use PDP/PEP terminology, ensure you define it (and cite your chosen reference):
- PDP (Policy Decision Point): evaluates a proposed action/plan and returns allow/deny.
- PEP (Policy Enforcement Point): blocks/allows execution based on policy decisions.
(NIST SP 800-207 defines a Zero Trust Architecture (ZTA) access model with policy decision and policy enforcement terminology; see References [8][9].)
Two reference architectures
A) LLM-led execution (authority in the model loop)

Conceptual flow (minimal):
request/context -> model -> tool_call(args) -> execute_tool -> observation -> model -> output
Where enforcement typically sits:
- Input shaping + tool schema constraints live close to the model call.
- If there is no external gate, tool execution is tightly coupled to model output.
Implication (bounded): If the application executes model-proposed tool calls with weak external gates, argument manipulation and injection-to-action failures have a short path to side effects.
B) Orchestrator-led execution (authority outside the model; control-plane gating)
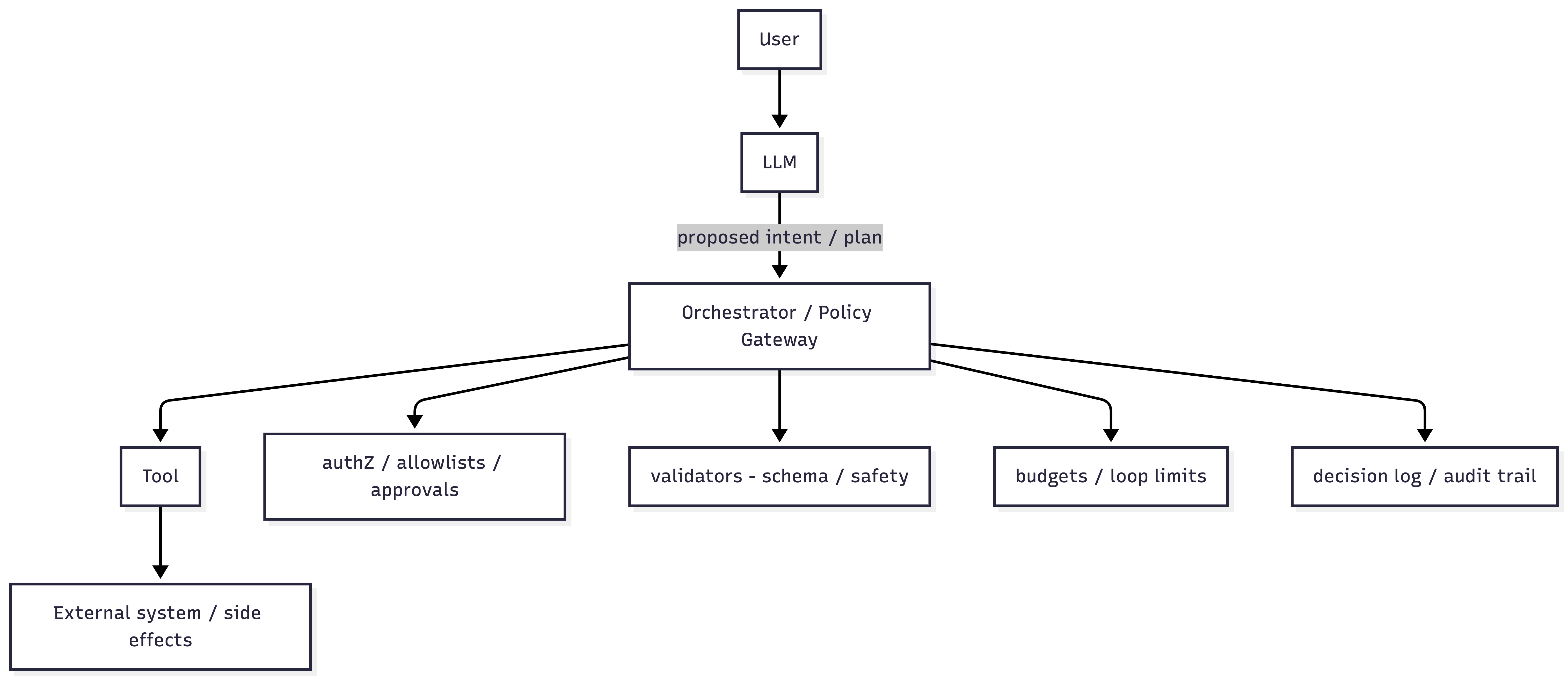
Conceptual flow (minimal):
request/context -> model proposes intent/step -> orchestrator validates/authorizes -> execute_tool -> observation -> model -> next step
Where enforcement typically sits:
- Orchestrator performs deny-by-default decisions before tool calls.
- Tool execution is a controlled transition from control plane to data plane.
Implication (bounded): This placement makes it feasible to enforce allowlists, budgets, and write gates independent of model compliance, because enforcement occurs in code before side effects.
Why this is an architecture decision (not a prompting decision)
Prompt text can express intent, but it is not (by itself) an enforcement boundary. When tools have side effects, failures that would otherwise produce incorrect text can translate into incorrect actions. That is why authority placement is a primary design axis.
Control-plane placement: what changes operationally
A practical way to compare patterns is to ask four questions:
1) Who selects the next step/tool?
2) Where is allow/deny enforced (before side effects)?
3) Where are budgets enforced (steps/time/cost/retries/tool calls)?
4) What evidence is recorded for postmortems (proposed → validated → executed)?
Enforcement-point map (control plane vs data plane)
| Function | LLM-led execution (typical placement) | Orchestrator-led execution (typical placement) |
|---|---|---|
| Tool selection | Model output | Orchestrator applies allowlist + intent gate |
| Argument validation | Sometimes weak or partial | Enforced in orchestrator (schema + semantic constraints) |
| Authorization for writes | Often prompt-driven or per-tool | Enforced server-side per call (write gate) |
| Budgets (steps/time/cost) | Harder to centralize inside the loop | Natural centralization point in orchestrator |
| Audit trail | Scattered across tool logs | Centralized decision evidence pipeline |
(“Typical placement” is an architectural tendency, not a guarantee.)
Decision matrix (summary)
| Dimension | LLM-led execution | Orchestrator-led execution |
|---|---|---|
| Where authority lives | In the model loop | External controller / control plane |
| Containment mechanisms | More dependent on model behavior | Can be enforced deterministically in code |
| Debuggability | Reconstruct from model + tool traces | Centralized decision evidence possible |
| Observability/audit | Often uneven unless standardized | Consistent event pipeline is straightforward |
| Latency | Often fewer hops in simple flows | Extra hop + validations can add latency |
| Cost governance | Must be added outside the model loop anyway | Natural centralization point for budgets/quotas |
| Injection-to-action path | Shorter if execution is prompt-driven | Can be lengthened by gates/allowlists |
Tradeoffs (architecture-first)
1) Reliability & failure containment
LLM-led execution
- Containment depends heavily on consistent model behavior across turns, especially in multi-step loops.
Orchestrator-led execution
- Enables deterministic containment mechanisms such as:
- precondition checks (state checks, idempotency keys),
- bounded retries/backoff,
- deny-by-default for side-effecting actions,
- fallback flows that are independent of model phrasing.
This is not a guarantee of correctness; it is control placement that makes deterministic containment feasible.
2) Debuggability & incident response
LLM-led execution
- Postmortems often require reconstructing behavior from model outputs and tool traces.
Orchestrator-led execution
- Centralizes structured decision evidence:
- what the model proposed,
- what validators returned,
- why a request was allowed/denied,
- what side effects were executed.
3) Observability & auditability
LLM-led execution
- Telemetry can be uneven across tools unless strongly standardized.
Orchestrator-led execution
- Makes a consistent event pipeline feasible:
- proposed intent → validated intent → authorization decision → executed side effects.
Concrete event schema (illustrative)
(Example only; not a standard.)
{
"request_id": "…",
"principal_id": "…",
"tenant_id": "…",
"proposed": { "intent": "…", "tool": "…", "args_hash": "…" },
"validated": { "allow": true, "policy_id": "…", "reasons": ["…"] },
"executed": { "tool": "…", "status": "ok", "duration_ms": 123 },
"budgets": { "steps_used": 3, "tool_calls_used": 2 }
}
4) Latency & throughput
This is implementation-dependent. Orchestrator-led patterns add validation/authorization hops; LLM-led patterns can be more direct in simple flows. In complex flows, external validation can stop unsafe or wasteful cascades early (loops, retries, tool churn), which may reduce downstream latency/cost (bounded statement).
5) Cost governance (tokens, tools, and loops)
OWASP treats unbounded consumption as a distinct risk category (LLM10:2025) [5]. Regardless of pattern, budgets must be enforced deterministically somewhere. Orchestrator-led designs commonly centralize:
- token/time/tool-call caps,
- tenant quotas,
- rate limits / backpressure, outside the model loop.
6) Product constraints (human-in-the-loop vs autonomy)
If product requirements include explicit confirmations (payments, deletes, privileged writes), orchestrator-led execution supports “no side effects without verified confirmation” as an enforceable rule (control-plane gate) independent of model compliance (bounded statement).
Security & governance (policy enforcement as one dimension)
Controls that should not live only in the prompt
OWASP’s GenAI Top 10 describes multiple classes of failures as application/system responsibilities, including:
- Prompt injection (LLM01:2025) [1]
- Improper output handling (LLM05:2025) [3]
- System prompt leakage (LLM07:2025) [4]
- Unbounded consumption (LLM10:2025) [5]
The OWASP prompt-injection prevention guidance also emphasizes instruction/data separation and treating external content as untrusted input [2].
Why authority placement affects injection-to-action risk
OWASP describes indirect prompt injection as instruction-like content embedded in external sources that can alter behavior when ingested [1][2]. Research literature analyzes similar patterns where untrusted content becomes an instruction channel [10].
If the model can directly trigger tools, injection-style failures are more likely to reach the action layer unless deterministic gates exist in an external control plane (bounded statement).
Tool restriction and argument validation
If you provide tool-calling to the model, it is common to restrict which tools are callable in a given step/intent category (deny-by-default) and to validate tool-call arguments in application code. (Precise API field names differ by vendor/runtime. NOT VERIFIED in this chat without fetching vendor docs; see References [12]–[14].)
Where MCP fits (integration layer ≠ governance layer)
MCP standardizes how tools/resources connect to AI applications (protocol and transports) [6]. MCP also includes security guidance for implementations [7]. MCP authorization is defined at the transport level for HTTP-based transports [11].
Practical implication: MCP can simplify tool connectivity, but enforcement still needs a policy/orchestrator layer: allowlists, approvals, argument validation, budgets, and auditable decisions.
Minimal implementation checklist (tool execution)
- Inventory tools; remove unused capabilities (reduce surface).
- Default-deny for side-effecting tools; require explicit allowlists per action.
- Enforce authorization outside the model (RBAC/ABAC, approvals).
- Validate tool arguments (schema, bounds, canonicalization).
- Validate/sanitize outputs before downstream execution (especially if executing, rendering, or storing).
- Treat retrieved content/tool metadata as untrusted input; defend against indirect prompt injection.
- Add budgets: token/time/tool-call limits and tenant quotas.
- Record a decision trail: proposed → validated → allowed/denied → executed.
Suggested next reads in this repo
- Tool-Using Systems: The Attack Surface Shifts to the Controller Loop
- How Agentic Control-Plane Failures Actually Happen
References
[1] OWASP GenAI Security Project — LLM01:2025 Prompt Injection
https://genai.owasp.org/llmrisk/llm01-prompt-injection/
[2] OWASP Cheat Sheet Series — LLM Prompt Injection Prevention Cheat Sheet
https://cheatsheetseries.owasp.org/cheatsheets/LLM_Prompt_Injection_Prevention_Cheat_Sheet.html
[3] OWASP GenAI Security Project — LLM05:2025 Improper Output Handling
https://genai.owasp.org/llmrisk/llm052025-improper-output-handling/
[4] OWASP GenAI Security Project — LLM07:2025 System Prompt Leakage
https://genai.owasp.org/llmrisk/llm072025-system-prompt-leakage/
[5] OWASP GenAI Security Project — LLM10:2025 Unbounded Consumption
https://genai.owasp.org/llmrisk/llm102025-unbounded-consumption/
[6] Model Context Protocol — Specification (2025-06-18)
https://modelcontextprotocol.io/specification/2025-06-18
[7] Model Context Protocol — Security Best Practices (2025-06-18)
https://modelcontextprotocol.io/specification/2025-06-18/basic/security_best_practices
[8] NIST SP 800-207 — Zero Trust Architecture (DOI)
https://doi.org/10.6028/NIST.SP.800-207
[9] NIST SP 800-207 — PDF
https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-207.pdf
[10] Greshake et al. (2023) — “Not what you’ve signed up for” (Indirect Prompt Injection), arXiv
https://arxiv.org/abs/2302.12173
[11] Model Context Protocol — Authorization (2025-06-18)
https://modelcontextprotocol.io/specification/2025-06-18/basic/authorization
[12] OpenAI API — Function calling
https://developers.openai.com/api/docs/guides/function-calling/
[13] OpenAI API — Chat API reference
https://developers.openai.com/api/reference/resources/chat/
[14] OpenAI API — Structured outputs
https://developers.openai.com/api/docs/guides/structured-outputs/