Security analysis of connected apps, external tools, and remote MCP servers in LLM systems, with emphasis on capability exposure, authorization scope, approval boundaries, external disclosure, and side-effect control.
Connected Apps Expand the Capability and Authorization Surface of LLM Systems
Subtitle: Once an LLM system is connected to external apps, tools, or remote MCP servers, the security problem shifts from prompt interpretation alone to capability exposure, scope control, approval, external disclosure, and downstream side effects.
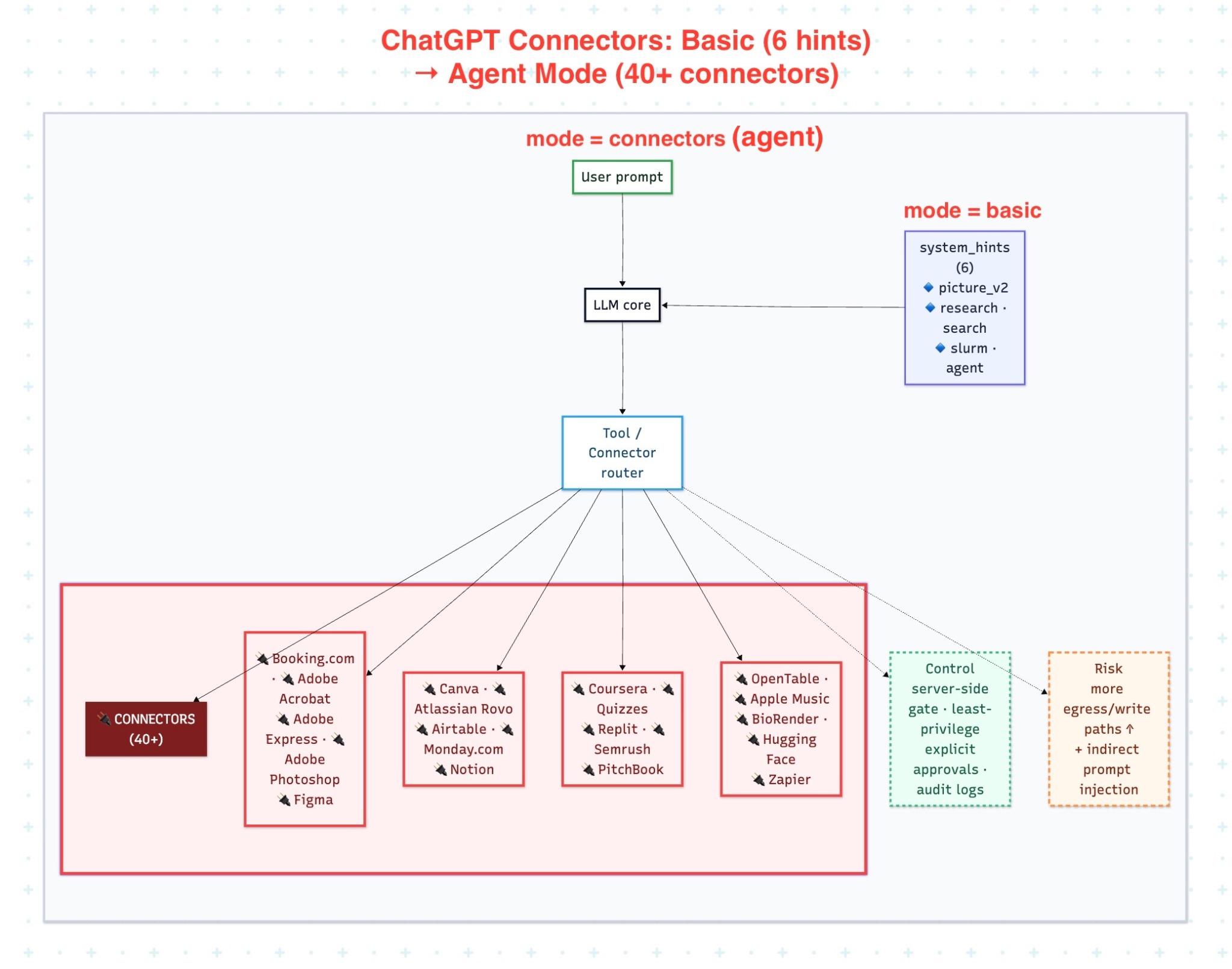
Tool-enabled LLM systems should not be analyzed as if they were only text interfaces. Once a model can call connected apps, external tools, or remote MCP servers, it no longer operates only over prompts and responses. It operates across capability boundaries that may expose external data, invoke remote services, and, in some architectures, produce state-changing effects. The main security question in this setting is not only whether the model interpreted a prompt correctly. The more important question is which capabilities become reachable, under which identity, with what scope, and with which approval and validation controls.
In this article, connected apps refers to external application integrations that extend an LLM system beyond text-only interaction. In ChatGPT product documentation, OpenAI renamed connectors to apps in December 2025. In API documentation, connectors still refers to OpenAI-maintained MCP wrappers for popular third-party services. Remote MCP servers refers to externally hosted capability providers exposed to the model through the Model Context Protocol. LLM-only workflow refers to a workflow limited to prompt interpretation and response generation without external tool invocation. Tool-enabled workflow refers to any workflow in which the model can invoke external capabilities, disclose context to outside systems, or trigger downstream actions. This article also distinguishes between read-only integrations, which retrieve or expose information, and side-effecting integrations, which can create, modify, send, approve, or otherwise change external state.
Why Connected Systems Change the Security Model
An LLM-only workflow is primarily a prompt-processing and output-generation system. A connected workflow is different. It introduces external capability paths: data retrieval, remote procedure calls, API interactions, third-party integrations, and, in some cases, state-changing actions. That changes the security model. The system must now govern not only prompt handling, but also authorization scope, external disclosure, approval policies, execution logging, and the conditions under which an action may occur.
This is why connected systems should be treated as a control-plane problem as much as a model-safety problem. The central issue is not merely whether the model can “use tools.” The issue is which tools are reachable, what permissions they inherit, what context may be disclosed to them, and what safeguards exist before a suggested action becomes an executed action. OWASP’s guidance for third-party MCP systems emphasizes authentication, authorization, secure discovery, sandboxing, governance workflows, least-privilege access, and human-in-the-loop oversight. Those are control-plane concerns, not merely prompting concerns.
Prompt Injection Still Matters, but It Is No Longer the Whole Problem
Prompt injection remains part of the threat model. OWASP defines indirect prompt injection as the case in which an LLM accepts input from external sources such as websites or files and that content alters model behavior in unintended ways. OWASP’s prompt-injection prevention guidance further explains that the root condition is the lack of clear separation between natural-language instructions and natural-language data. In tool-enabled systems, that risk can propagate into action paths, not only model outputs.
But connected systems introduce a broader security question. Even if prompt injection were tightly controlled, the system would still need to answer several control-plane questions:
- Which external capabilities are exposed?
- Which integrations are read-only and which are side-effecting?
- Which principal is the action executed under?
- Which data may be sent to a third-party system?
- Which operations require explicit approval?
- What evidence is preserved for audit and attribution?
Those questions are not implementation details. In connected systems, they are part of the primary security design.
Risk Class 1: Capability Expansion Without Sufficient Scope Control
The first risk is overexposure of capability. Once a model is connected to multiple apps, tools, or remote MCP servers, it may be able to access more systems, more data, and more actions than the user intended or the task required. This is a classic least-privilege failure.
The security problem here is not only that the model has “many tools.” The problem is that capability exposure and authorization scope are not minimized. A connected system becomes fragile when it gives the model broad access to external systems, broad data visibility, or broad action authority without strict scoping by task, identity, tenant, or approval context.
From an engineering perspective, this is where read-only and side-effecting tools must be treated differently. A search integration, a document-retrieval integration, and a send-or-update integration are not equivalent risk classes. They require different policies, different approval expectations, and different logging requirements. Treating all integrations as generic “tools” hides the real control problem.
Risk Class 2: Approval and Execution Drift
The second risk is drift between user intent, model interpretation, and executed action. In a connected workflow, a model may propose an action, select a tool, construct arguments, or trigger a downstream step. If that path is not constrained by explicit approval and deterministic validation, the system can execute something broader or different from what the user intended.
This risk is especially important for side-effecting operations. A workflow that reads from an external system and a workflow that sends, updates, deletes, approves, or posts to an external system should not share the same approval posture. OWASP’s guidance for third-party MCP usage emphasizes human-in-the-loop oversight, governance workflows, and strong authorization controls for externally connected systems. OpenAI’s tooling guidance also reflects an approval model for connected capabilities, including the distinction between operations that may be allowed automatically and operations that should require confirmation.
The professional design principle is simple: the model may suggest; the system must decide. Model output can propose a next step, but execution policy should be enforced by deterministic controls that verify scope, identity, operation type, and approval requirements before any external effect occurs.
Risk Class 3: External Disclosure and Egress Through Connected Tools
The third risk is external disclosure. A connected system can leak more than it writes. OpenAI’s safety guidance warns that models may send more information to connected systems than users expect or intend. In practical terms, a model may over-share task context, internal identifiers, sensitive fragments, or intermediate artifacts through tool calls, retrieval queries, or follow-up actions.
This is why data minimization must apply to outbound context, not only to stored data. A secure connected system should tightly constrain what context can be sent to each integration, which fields are allowed to cross the boundary, and whether the destination system is permitted to receive them at all. In many architectures, the most important boundary is not a write API. It is the outbound disclosure path.
This risk also intersects with prompt injection and downstream misuse. OWASP’s AI Agent Security Cheat Sheet explicitly calls out prompt injection through external data sources, tool abuse and privilege escalation, and data exfiltration through tool calls or agent outputs. In other words, once external tools are reachable, the system must defend both against unsafe actions and against unsafe disclosure.
Risk Class 4: Third-Party Integration and Remote MCP Trust
The fourth risk is third-party trust. Remote MCP servers and third-party integrations are not neutral extensions of the model. They are separately operated systems with their own security properties, their own discovery and authentication mechanisms, and their own failure modes. OWASP’s practical guide for securely using third-party MCP servers focuses on authentication, authorization, secure server discovery, client sandboxing, least privilege, and governance workflows precisely because these systems introduce external trust dependencies into the execution path.
That matters because the risk is no longer limited to model behavior. It now includes server authenticity, credential handling, token scope, discovery integrity, and whether a third-party tool can induce unsafe behavior or receive excessive context. The security review of a connected LLM system therefore has to include the connected services themselves, not only the model orchestration layer.
Prompt Injection in Connected Systems: The Correct Boundary
Connected systems still need a clear prompt-injection boundary. OWASP states that indirect prompt injection can arise from websites or files. In a connected architecture, that means externally retrieved content should never directly govern tool selection, tool arguments, approval bypass, or downstream state changes. OpenAI’s safety guidance aligns with the same rule: untrusted data should not directly drive agent behavior.
This distinction is critical. Retrieved content may inform analysis. It may support a content judgment such as “this external page claims X.” It must not directly determine an operational step such as “call this tool,” “send this request,” or “approve this action.” When that separation fails, the system no longer has a content-processing problem alone. It has a control failure across an external capability boundary.
Control Model for Connected LLM Systems
A defensible control model for connected systems has six requirements.
1. Expose the minimum set of integrations
Only the tools and apps required for the task should be reachable. This is the least-privilege baseline for connected capabilities.
2. Separate read-only from side-effecting operations
Read access, retrieval access, and state-changing access should not share the same approval model, policy controls, or trust assumptions.
3. Bind permissions to the correct principal and scope
External actions should run under the correct user, tenant, or delegated identity, with scope constrained to the specific task and service boundary.
4. Minimize outbound disclosure
The system should restrict what context, identifiers, and content may be sent to each external integration. Outbound data flow is a primary security surface, not an implementation detail.
5. Require explicit approval for meaningful side effects
High-impact operations should require confirmation or another deterministic authorization step before execution.
6. Log and attribute every external action path
The system should preserve enough evidence to answer: which tool was called, under which identity, with which scope, using which arguments, and with what result. Without this, post-incident reconstruction and accountability become weak even if execution controls exist.
Conclusion
Connected apps, external tools, and remote MCP servers do not merely extend what an LLM system can access. They expand what the system may be able to do. That changes the security problem. The core challenge is no longer only prompt interpretation. It is governance over exposed capabilities: which integrations are reachable, which operations are read-only versus side-effecting, what data may cross external boundaries, what approvals are required, and how every external action is validated and attributed.
For that reason, connected LLM systems should be designed and reviewed as control-plane systems. Prompt injection remains relevant, especially through external data sources, but it is only one part of the security model. The broader requirement is stronger: minimize capability exposure, constrain authorization scope, prevent unnecessary disclosure, require approval for material side effects, and treat third-party integrations as security-relevant execution dependencies rather than convenience features.
Suggested reading
- The Attack Surface Isn’t the LLM — It’s the Controller Loop
- How Agentic Control-Plane Failures Actually Happen
- Request assembly threat model: reading the diagram
- Agentic Systems: 8 Trust-Boundary Audit Checkpoints
- Web-Retrieved Content Is a Prompt-Injection Boundary in Tool-Using LLM Systems
- Engineering Quality Gate — Procedure
References
| [1]: https://developers.openai.com/api/docs/guides/tools-connectors-mcp/ “MCP and Connectors | OpenAI API” |
| [2]: https://help.openai.com/en/articles/11487775-connectors-in-chatgpt “Apps in ChatGPT | OpenAI Help Center” |
| [3]: https://genai.owasp.org/llmrisk/llm01-prompt-injection/ “LLM01:2025 Prompt Injection | OWASP GenAI Security Project” |
| [4]: https://developers.openai.com/api/docs/guides/agent-builder-safety/ “Safety in building agents | OpenAI API” |
| [5]: https://genai.owasp.org/resource/cheatsheet-a-practical-guide-for-securely-using-third-party-mcp-servers-1-0/ “A Practical Guide for Securely Using Third-Party MCP Servers 1.0 | OWASP GenAI Security Project” |
| [6]: https://cheatsheetseries.owasp.org/cheatsheets/LLM_Prompt_Injection_Prevention_Cheat_Sheet.html “LLM Prompt Injection Prevention Cheat Sheet | OWASP Cheat Sheet Series” |
| [7]: https://cheatsheetseries.owasp.org/cheatsheets/AI_Agent_Security_Cheat_Sheet.html “AI Agent Security Cheat Sheet | OWASP Cheat Sheet Series” |