Threat model and control model for browsing-enabled LLM systems where external content can influence routing, tool parameters, downstream tool calls, or state-changing actions.
Web-Retrieved Content Is a Prompt-Injection Boundary in Tool-Using LLM Systems
Subtitle: External content may inform analysis, but it must not directly govern routing, tool arguments, or state-changing actions.
Thesis
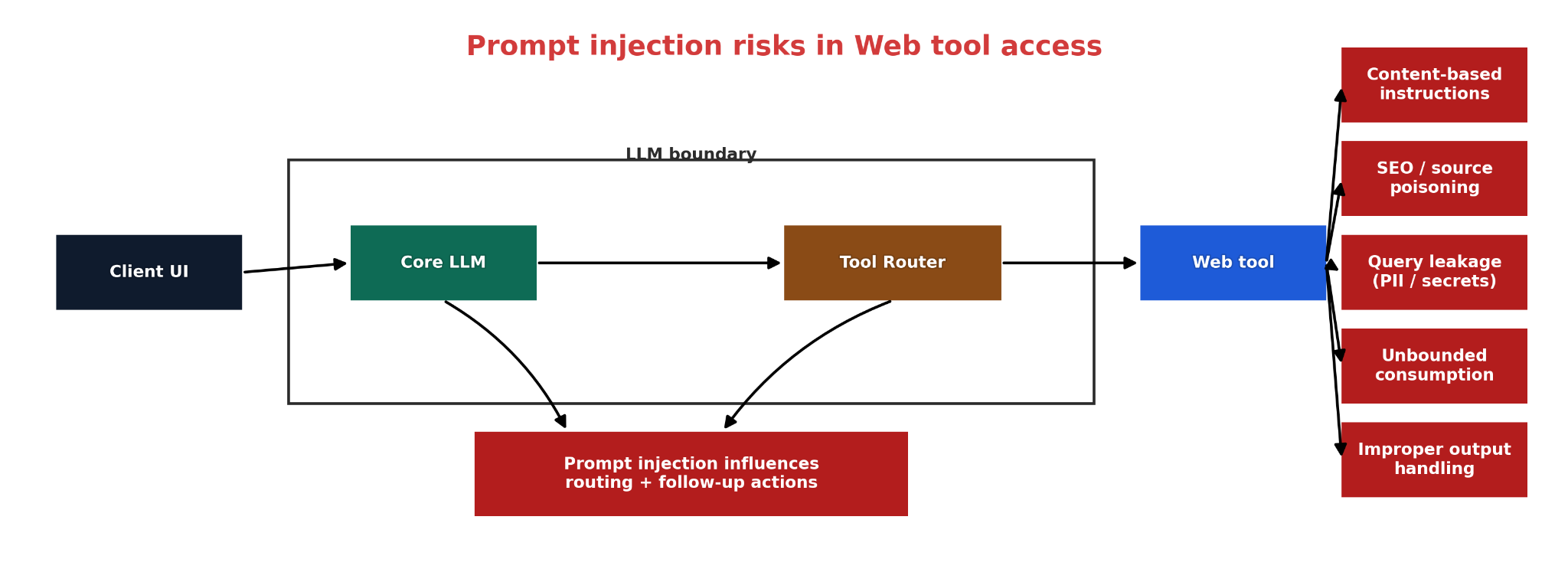
In this article, trust boundary means the point at which externally retrieved content enters a workflow and can influence what the system does next. In a tool-using LLM system, that boundary appears when content fetched from the web is allowed to affect routing, tool parameters, follow-up calls, or downstream actions. OWASP defines indirect prompt injection as the case in which an LLM accepts input from external sources such as websites or files and that content changes model behavior in unintended ways. NIST describes the same attack class as adversarial prompts injected into data likely to be retrieved by LLM-integrated applications. OpenAI’s guidance states the operational consequence directly: untrusted text or data can alter model behavior, trigger misaligned actions, or enable private-data exfiltration through downstream tool calls.
The primary risk class is therefore prompt injection through retrieved content. Other risks may appear, but they are secondary and architecture-dependent. If retrieved content can trigger damaging actions, the design may also create excessive agency risk. If model output derived from retrieved content is passed downstream without validation, the design may also create improper output handling risk. The important analytical point is that browsing does not automatically create every LLM risk category at once; it creates a prompt-injection boundary first.
What Must Be Protected
The security property that matters is not “never read malicious content.” A browsing-enabled system cannot guarantee that. The relevant property is stricter: retrieved content must remain non-authoritative. It may contribute evidence for an answer, but it must not directly determine which tool runs next, what arguments are sent to that tool, whether a side effect is allowed, or how stored state changes. OpenAI’s agent-safety guidance aligns with this control model: untrusted data should never directly drive agent behavior, and systems should extract only narrowly defined structured fields from external inputs when information must pass between workflow stages.
This is the core distinction that many systems fail to preserve. OWASP’s prompt-injection prevention guidance explains that LLM applications often process instructions and data without a reliable separation between them. A web-retrieval pipeline intensifies that problem because externally fetched content can arrive inside the same execution context that later governs tool use or action selection. Once that separation is lost, the retrieval step is no longer just content access; it becomes part of the control path.
Threat Model
A representative execution path is:
user request → model interpretation → retrieval or browsing → model output derived from retrieved content → downstream tool use or action
The attack does not require a compromised browser in the conventional sense. It requires only that attacker-controlled or attacker-influenced content be retrieved and then treated as behaviorally relevant by later workflow steps. OWASP explicitly states that indirect prompt injection can come from websites or files. NIST states that such attacks target data likely to be retrieved by LLM-integrated applications. OpenAI’s tooling guidance adds the same warning in operational terms: any external content fetched over the network may contain hidden instructions intended to manipulate model behavior.
This is why “the browser is read-only” is not a sufficient security claim. Read access to adversarial content can still influence later decisions. OpenAI’s agent-safety documentation warns that risk rises when arbitrary text influences tool calls, and its deep-research guidance notes that prompt injection can be embedded directly in the body of a web page or in text returned by retrieval systems, with downstream consequences such as exfiltration.
Failure Mode 1: Retrieved Content Steers Later Decisions
The first failure mode is the most direct. A retrieval step fetches content that contains instruction-like payloads, hidden directives, or adversarial suggestions. If the model is then allowed to treat that content as guidance for what to do next, the system has crossed the trust boundary incorrectly. OWASP defines that pattern as indirect prompt injection. NIST describes the same mechanism as adversarial prompts embedded in retrievable data.
The technical failure is not “the model saw malicious text.” The failure is that the architecture did not preserve a hard distinction between content to analyze and instructions that may govern behavior. In a secure design, retrieved text may influence a content judgment such as “this page appears to claim X,” but it must not directly influence execution choices such as “call this tool,” “use these arguments,” or “advance to this state.” OpenAI’s agent-safety guidance captures the same design rule by recommending that untrusted data never directly drive agent behavior.
Failure Mode 2: Retrieval Workflows Disclose More Context Than Intended
A second failure mode occurs during the retrieval process itself. Search queries, follow-up lookups, and connected tool calls can disclose more context than the user or developer intended. OpenAI states that a model may send more data to a connected MCP than expected, and that developers do not have full control over what the model chooses to share with connected systems. In practice, that means a retrieval workflow can leak internal identifiers, sensitive fragments, or unnecessary user context during search and follow-up calls even before any downstream action is taken.
This is why least privilege must apply to retrieval, not only to write-capable tools. A secure system should minimize what context is exposed to search and lookup tools, minimize which follow-up calls are allowed, and bind permissions to the caller’s actual context rather than to a generic privileged identity. OWASP’s excessive-agency guidance attributes damaging outcomes to excessive functionality, excessive permissions, and excessive autonomy. That logic applies directly to retrieval workflows that can over-share, over-fetch, or escalate without independent checks.
Failure Mode 3: Derived Output Flows Downstream Without Deterministic Validation
The third failure mode appears after retrieval. A model reads external content, produces a summary, extracts fields, generates a plan, or proposes a next step, and that output is then consumed by another component. OWASP defines improper output handling as insufficient validation, sanitization, and handling of LLM outputs before they are passed downstream to other components or systems. OWASP also notes why this matters: because model output can be controlled by prompt input, unsafe downstream use is similar to giving users indirect access to additional functionality.
OpenAI recommends a compatible mitigation strategy: constrain data flow with structured outputs and isolate untrusted data between workflow nodes. Structured Outputs ensure that model responses adhere to a supplied JSON Schema. That is useful because it constrains shape, field names, and type expectations. It does not, by itself, replace policy validation in the receiving component. A downstream system still has to decide whether the proposed value is allowed in the current context. Schema conformance is a transport control; admissibility is still an application-policy decision.
Control Model
A defensible engineering model for browsing-enabled LLM systems has six requirements.
1. Treat retrieved content as untrusted input by default.
External network content and retrieved text should enter the workflow with the same suspicion as any other attacker-controlled input. OpenAI’s tooling guidance explicitly warns that network-fetched content may contain hidden instructions intended to manipulate behavior.
2. Separate content interpretation from action selection.
The model may analyze retrieved content, but a deterministic layer should decide whether any downstream tool, state change, or privileged action is allowed. OpenAI’s agent-safety guidance recommends designing workflows so that untrusted data never directly drive agent behavior.
3. Pass only allowlisted structured fields across workflow boundaries.
When information must move from retrieval to later stages, extract only narrowly defined values such as enums, identifiers, or validated JSON fields. OpenAI recommends structured outputs for this purpose and guarantees schema adherence, which reduces free-form propagation paths.
4. Constrain retrieval capability and disclosure.
The system should limit which tools can be called after retrieval, what context may be disclosed during queries, and how much autonomy the model has to continue searching or chaining actions. OWASP’s excessive-agency guidance identifies excessive functionality, permissions, and autonomy as the root causes of damaging actions.
5. Require explicit approval for meaningful side effects.
OpenAI’s agent-safety and tool guidance recommend confirmation or approval for high-impact operations. If retrieved content can influence a workflow that reaches write paths, external services, or user-visible side effects, approval should be part of the design rather than an afterthought.
6. Validate every downstream handoff as if it came from an untrusted actor.
OWASP’s improper-output-handling guidance requires validation and sanitization before model output reaches downstream components. In practice, that means validating not only syntax and schema but also whether the proposed value, tool, target, or action is permissible under current policy.
Conclusion
Web retrieval in a tool-using LLM system should be modeled as a prompt-injection boundary. The boundary exists because externally retrieved content can enter the workflow and influence later behavior unless the system prevents that influence from becoming authoritative. OWASP, NIST, and OpenAI all describe the same core problem from different angles: attacker-influenced content can be retrieved indirectly, alter model behavior, and create downstream harm if the workflow is not tightly constrained. The correct response is architectural rather than rhetorical: keep retrieved content non-authoritative, separate analysis from action, constrain retrieval and tool use, and validate every downstream handoff before it can affect a trusted component.
Suggested reading
- The Attack Surface Starts Before Agents — The LLM Boundary
- How Agentic Control-Plane Failures Actually Happen
- Connected Apps Expand the Capability and Authorization Surface of LLM Systems
- Agentic Systems: 8 Trust-Boundary Audit Checkpoints
- Request assembly threat model: reading the diagram
- Engineering Quality Gate — Procedure